Contents
50.
Этапы трансляции. Общая схема
работы транслятора.
51. Понятие прохода. Однопроходные и многопроходные
компиляторы.
52. Компиляторы. Трансляторы. Интерпретаторы и
Ассемблеры.
53.Назначение трансляторов, компиляторов и
интерпретаторов. Примеры реализации.
56. Понятие языка, синтаксис, семантика.
Формальные и естественные языки. Языки программирования
57. Понятие грамматики. Формальное определение
грамматики. Форма Бэкуса-Наура.
58. Классификация грамматик. Четыре типа
грамматик по Хомскому.
59. Классификация языков. Примеры классификации
языков и грамматик.
60. Понятие системы программирования, её состав.
62.Средства тестирования и отладки программ.
50. Этапы трансляции. Общая схема работы транслятора.
Часто
путают транслятор с языка программирования и систему программирования. Хотя
«система программирования»- понятие гораздо большее, чем транслятор.
Транслятор
- это программа, которая переводит (с англ. translate) с
нотации одного языка в нотацию другого языка.
Трансляторы
могут быть интерпретаторами (interpreter), т.е. совмещать анализ
исходной программы с ее выполнением. Различие тут в том, что результатом работы
интерпретатора будет не машинный код, а последовательность обращений к
библиотеке функций интерпретатора.
Интерпретатор
в отличие от компилятора может выбирать одну за другой инструкции и сразу их
выполнять. При интерпретации (это важно!!!), в отличии
от трансляции или компиляции, может быть начато выполнение программы, которая
содержит синтаксические ошибки.
Кросс-трансляторы
(кросс-компиляторы) - это вид трансляторов, которые переводят программу,
записанную в нотации одного языка программирования и выполняющуюся в одной
инструментальной среде, на одной ЭВМ, которая характеризуется своим
операционным окружением и/или архитектурой, в код вычислительной системы другой
среды другой ЭВМ.

Редактор
внешних связей моделирует размещение объектных модулей в ОП и разрешает все
связи между ними.
Иногда
трансляторы в качестве результата трансляции выдают модуль на ассемблере
соответствующей машины.
В
вышерассмотренную схему можно добавит этап оптимизации программы, причем
оптимизация может происходить до этапа трансляции (т.е. в терминах исходного
языка) и/или после трансляции (в терминах машинного кода). Например, до
трансляции вычислить все const-ые
выражения. Этот этап особенно важен для класса машин, относящихся к mainframe-ам.
Этап
трансляции. Каждый транслятор при обработке программы выполняет следующие
действия:
• лексический анализ;
• синтаксический анализ;
• семантический анализ и генерация кода.
51. Понятие прохода. Однопроходные и многопроходные
компиляторы.
«Проход компиляции» - процесс полного
просмотра (сканирования) исходного текста программы компилятором, его обработки
и получения некоторых промежуточных результатов.
Логически
работу компилятора можно представить в виде отдельных этапов и фаз на этих
этапах, а физически - в виде проходов.
Однопроходные
компиляторы. Процесс полной компиляции программы выполняется при однократном
чтении кода. Различные фазы выполняются параллельно, что является очень
удобным.
Многопроходные
компиляторы. Получают объектный модуль не за один раз, а за несколько проходов.
Результатом промежуточных проходов является некоторое внутреннее представление
программы. Результатом последнего прохода является объектный модуль.
Количество
проходов является важной технической характеристикой компилятора. Разработчики
пытаются понизить количество проходов компиляторов для увеличения скорости
работы и уменьшения объема необходимой памяти. Идеальный вариант -
однопроходный компилятор, однако не всегда количество проходов можно уменьшить,
т.к. количество проходов определяется грамматикой языка и семантическими
правилами.
Компилятор
с языка Си является двухпроходным:
1
проход - предпроцессорный, т.е. когда выполняются подстановки;
2 проход
- лексический, синтаксический и семантический анализ. Результатом является
объектный модуль.
Первые
компиляторы были 7-ми и 8-ми - проходные по причине нехватки памяти.
52. Компиляторы. Трансляторы. Интерпретаторы и
Ассемблеры.
Ассемблеры- трансляторы с языка ассемблера. Язык ассемблер - это язык
низкого уровня. Структура и взаимосвязь цепочек языка близки
к машинным командам вычислительной системы, где должна выполняться
результирующая программа. Применение языка ассемблера позволяет разработчику
управлять ресурсами вычислительной системы (ЦП, ОП, внешние устройства и т.д.)
на уровне машинных команд. Каждая команда исходной программы на языке
ассемблере в результате компиляции преобразуется в 1 машинную команду.
Транслятор с языка ассемблера часто называется «ассемблер» или «программа
ассемблера».
Транслятор
- это программа, которая переводит (с англ. translate) с
нотации одного языка в нотацию другого языка.
Компилятор
- это транслятор, который переводит программу из нотации одного языка в нотацию
машинного языка. Машинным языком может быть код конкретной машины, любой
объектный код.
Трансляторы
могут быть интерпретаторами (interpreter), т.е. совмещать анализ
исходной программы с ее выполнением. Различие тут в том, что результатом работы
интерпретатора будет не машинный код, а последовательность обращений к
библиотеке функций интерпретатора.
Интерпретатор
в отличие от компилятора может выбирать одну за другой инструкции и сразу их
выполнять. При интерпретации (это важно!!!), в отличии
от трансляции или компиляции, может быть начато выполнение программы, которая
содержит синтаксические ошибки.
53.Назначение
трансляторов, компиляторов и интерпретаторов. Примеры реализации.
Транслятор (англ. translator — переводчик) — это
программа-переводчик. Она преобразует программу, написанную на одном из языков
высокого уровня, в программу, состоящую из машинных команд.
Трансляторы реализуются
в виде компиляторов или интерпретаторов. С точки зрения выполнения работы
компилятор и интерпретатор существенно различаются.
Компилятор (англ. compiler — составитель,
собиратель) читает всю программу целиком, делает ее перевод и создает
законченный вариант программы на машинном языке, который затем и выполняется.
Интерпретатор (англ. interpreter — истолкователь,
устный переводчик) переводит и выполняет программу строка за строкой.
После того, как
программа откомпилирована, ни сама исходная программа, ни компилятор более не нужны. В то же время программа, обрабатываемая
интерпретатором, должна заново переводиться на машинный язык при каждом
очередном запуске программы.
Откомпилированные
программы работают быстрее, но интерпретируемые проще исправлять и изменять.
Каждый конкретный язык
ориентирован либо на компиляцию, либо на интерпретацию — в зависимости от того,
для каких целей он создавался. Например, Паскаль обычно используется для
решения довольно сложных задач, в которых важна скорость работы программ.
Поэтому данный язык обычно реализуется с помощью компилятора. С другой стороны,
Бейсик создавался как язык для начинающих программистов, для которых построчное
выполнение программы имеет неоспоримые преимущества.
Примеры реализации
компиляторов C++, Pascal, Delphi
Примеры реализации
интерпретаторов Java, SQL, PHP
54.
Лексические анализаторы. Назначение.
Принципы организации. Автоматизация построения лексических
анализаторов: LEX.
Основная задача лексического
анализа - разбить входной текст, состоящий из последовательности одиночных
символов, на последовательность слов, или лексем, т.е. выделить эти слова из
непрерывной последовательности символов. Все символы входной последовательности
с этой точки зрения разделяются на символы, принадлежащие каким-либо лексемам,
и символы, разделяющие лексемы (разделители). В некоторых случаях между
лексемами может и не быть разделителей. С другой стороны, в некоторых языках
лексемы могут содержать незначащие символы (например, символ пробела в
Фортране). В Си разделительное значение символов-разделителей может
блокироваться («\» в конце строки внутри "...").
Обычно все лексемы делятся на
классы. Примерами таких классов являются числа (целые, восьмеричные, шестнадцатиричные, действительные и т.д.), идентификаторы,
строки. Отдельно выделяются ключевые слова и символы пунктуации (иногда их
называют символы-ограничители). Как правило, ключевые слова - это некоторое
конечное подмножество идентификаторов. В некоторых языках (например, ПЛ/1) смысл лексемы может зависеть от ее контекста и
невозможно провести лексический анализ в отрыве от синтаксического.
С точки зрения дальнейших фаз
анализа лексический анализатор выдает информацию двух сортов: для синтаксического
анализатора, работающего вслед за лексическим,
существенна информация о последовательности классов лексем, ограничителей и
ключевых слов, а для контекстного анализа, работающего вслед за синтаксическим,
важна информация о конкретных значениях отдельных лексем (идентификаторов,
чисел и т.д.).
Для автоматизации разработки
лексических анализаторов было разработано довольно много средств. Как правило,
входным языком для них служат либо праволинейные
грамматики, либо язык регулярных выражений. Одной из наиболее распространенных
систем является LEX, работающий с расширенными
регулярными выражениями. LEX-программа состоит из трех частей: Объявления
%%
Правила трансляции
%%
Вспомогательные подпрограммы
Секция объявлений включает
объявления переменных, констант и определения регулярных выражений. При
определении регулярных выражений могут использоваться следующие конструкции: [abc] - либо a, либо b, либо c;
[a-z] - диапазон символов;
R* - 0 или более повторений регулярного
выражения R;
R+ - 1 или более повторений регулярного
выражения R;
R1/R2 - R1, если за ним следует R2;
R1|R2 - либо R1, либо
R2;
R? - если есть R,
выбрать его;
R$ - выбрать R, если
оно последнее в строке;
^R - выбрать R, если
оно первое в строке;
[^R] - дополнение к R;
R{n,m} - повторение R от n до m раз;
{имя} - именованное регулярное
выражение;
(R)
- группировка.
Правила трансляции LEX
программ имеют вид p_1 { действие_1 }
p_2 { действие_2 }
................
p_n { действие_n }
где каждое p_i -
регулярное выражение, а каждое действие_i -
фрагмент программы, описывающий, какое действие должен сделать лексический
анализатор, когда образец p_i
сопоставляется лексеме. В LEX действия записываются на Си.
Третья секция содержит
вспомогательные процедуры, необходимые для действий. Эти процедуры могут
транслироваться раздельно и загружаться с лексическим анализатором.
Лексический анализатор,
сгенерированный LEX, взаимодействует с синтаксическим анализатором следующим
образом. При вызове его синтаксическим анализатором лексический анализатор
посимвольно читает остаток входа, пока не находит самый длинный префикс,
который может быть сопоставлен одному из регулярных выражений p_i. Затем
он выполняет действие_i. Как
правило, действие_i возвращает управление
синтаксическому анализатору. Если это не так, т.е. в соответствующем действии
нет возврата, то лексический анализатор продолжает поиск лексем до тех, пока
действие не вернет управление синтаксическому анализатору. Повторный поиск
лексем вплоть до явной передачи управления позволяет лексическому анализатору
правильно обрабатывать пробелы и комментарии. Синтаксическому анализатору
лексический анализатор возвращает единственное значение - тип лексемы. Для
передачи информации о типе лексемы используется глобальная переменная yylval.
Текстовое представление выделенной лексемы хранится в переменной yytext, а ее
длина в переменной yylen.
Схема построения лексического анализатора:

55.
Синтаксические анализаторы. Основные принципы
работы. Автоматизация построения синтаксических анализаторов: YACC.
Синтаксический анализ
(синтаксический анализатор) - фаза компиляции, на которой определяется общая
структура программы. Синтаксический анализатор должен обладать информацией о
контексте программы, т.е. учитывать значение прочитанных символов. Результатом
работы синтаксического анализатора является представление программы в виде
синтаксического дерева.
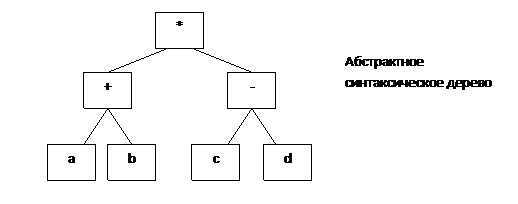
Основные принципы работы
синтаксического анализатора
Синтаксический анализатор
(синтаксический разбор) — это часть компилятора, которая отвечает за выявление
основных синтаксических конструкций входного языка. В задачу синтаксического
анализа входит: найти и выделить основные синтаксические конструкции в тексте
входной программы, установить тип и проверить правильность каждой
синтаксической конструкции и, наконец, представить синтаксические конструкции в
виде, удобном для дальнейшей генерации текста результирующей программы.
В основе синтаксического
анализатора лежит распознаватель текста входной программы на основе грамматики
входного языка. Распознаватель дает ответ на вопрос о том, принадлежит или нет
цепочка входных символов заданному языку. Синтаксический разбор — это основная
часть компилятора на этапе анализа. Без выполнения синтаксического разбора
работа компилятора бессмысленна, в то время как лексический разбор в принципе
является необязательной фазой. Все задачи по проверке синтаксиса входного языка
могут быть решены на этапе синтаксического разбора. Сканер только позволяет
избавить сложный по структуре синтаксический анализатор от решения примитивных
задач по выявлению и запоминанию лексем исходной программы.
Синтаксический анализатор
воспринимает выход лексического анализатора и разбирает его в соответствии с
грамматикой входного языка. Однако в грамматике входного языка программирования
обычно не уточняется, какие конструкции следует считать лексемами. Примерами
конструкций, которые обычно распознаются во время лексического анализа, служат
ключевые слова, константы и идентификаторы. Но эти же конструкции могут
распознаваться и синтаксическим анализатором. На практике не существует
жесткого правила, определяющего, какие конструкции должны распознаваться на
лексическом уровне, а какие надо оставлять синтаксическому анализатору. Обычно
это определяет разработчик компилятора. Основу любого синтаксического
анализатора всегда составляет распознаватель, построенный на основе какого-либо
класса КС-грамматик. Поэтому главную роль и том, как функционирует
синтаксический анализатор и какой алгоритм лежит в его основе, играют принципы
построения распознавателей КС-языков.
Автоматизация построения
синтаксических анализаторов (программа YACC)
Автоматизированное построение
синтаксических анализаторов может быть выполнено с помощью программы YACC.
Программа YACC (Yet Another Compiler Compiler)
предназначена для построения синтаксического анализатора контекстно-свободного
языка. Анализируемый язык описывается с помощью грамматики к пиле, близком
форме Бэкуса— Наура (нормальная форма Бэкуса—Наура —
НФБН). Результатом работы YACC является исходный текст программы
синтаксического анализатора. Анализатор, который порождается YACC,
реализует восходящий LALR(l) распознаватель.
Исходная грамматика для YACC
состоит из трех секций, разделенных символом %%, — секции описаний, секции
правил, в которой описывается грамматика, и секции программ, содержимое которой
просто копируется в выходной файл. Например, ниже приведено описание простейшей
грамматики для YACC, которая соответствует грамматике арифметических
выражений:
%token a
%start e
%
e : e ‘+‘ m | e ‘-‘
m | m
m : m ‘*’ t | m ‘/’
t | t
a : a | ‘(’ e ‘)’ :
%%
Секция описаний содержит
информацию о том, что идентификатор а является лексемой (терминальным символом)
гpамматики, а
символ е — ее начальным нетерминальным символом.
Грамматика, записана обычным образом
— идентификаторы обозначают терминальные и нетерминальные символы; символьные
константы типа '+' и '-' считаются терминальными
символами. Символы :, |, ; принадлежат к метаязыку YACC и
читаются согласно НФБН «есть по определению», «или» и «конец правила»
соответственно.
В отличие от LEX,
который всегда способен состроить лексический распознаватель, если входной файл
содержит правильное регулярное выражение, YACC не
всегда может построить распознаватель, даже если входной язык задан правильной
КС-грамматикой. Ведь заданная грамматика может и не принадлежать к классу LALR(l). В
этом случае YACC выдаст сообщение об ошибке (наличии неразрешимого LALR(t)
конфликта в грамматике) при построении синтаксического анализатора. Тогда
пользователь должен либо преобразовать грамматику, либо задать YACC
некоторые дополнительные правила, которые могут облегчить построение
анализатора. Например, YACC позволяет указать правила, явно задающие
приоритет операций и порядок их выполнения (слева направо или справа налево).
С каждым правилом грамматики
может быть связано действие, которое будет выполнено при свертке по данному
правилу. Оно записывается в виде заключенной в фигурные скобки
последовательности операторов языка, на котором порождается исходный текст программы распознавателя (обычно это язык С).
Последовательность должна располагаться после правой части соответствующего
правила. Также YACC позволяет управлять действиями, которые будут
выполняться распознавателем в том случае, если входная цепочка не принадлежит
заданному языку. Распознаватель имеет возможность выдать сообщение об ошибке,
остановиться либо же продолжить разбор, предпринял некоторые действия,
связанные с попыткой локализовать либо устранить ошибку во входной цепочке.
Схема построения синтаксического анализатора:

56. Понятие
языка, синтаксис, семантика. Формальные и естественные языки. Языки программирования
Язы́к — знаковая
система, соотносящая понятийное
содержание и типовое звучание (написание).
Синтаксис (построение, порядок, составление) - система правил,
определяющих допустимые конструкции языка программирования из букв алфавита.
Семантика (смысловое значение)-
система правил однозначного толкования каждой языковой конструкции, позволяющих
производить процесс обработки данных.
Формальный язык - это множество
конечных слов над конечным
алфавитом. К формальным
языкам относиться, например, компьютерный язык
Есте́ственный язы́к — в лингвистике и философии
языка язык, используемый для общения людей и не созданный искусственно.
Компьютерный язык - этот термин соответствует понятию языка программирования, однако это соответствие не является
вполне однозначным. Так, например, языки разметки (такие как HTML) не являются языками программирования, однако
определённо относятся к компьютерным языкам.
Языки программирования - это формальные искусственные языки.
Как и естественные языки, они имеют алфавит, словарный запас, грамматику и синтаксис,
а также семантику.
Взаимодействие
синтаксических и семантических правил определяет основные понятия языка, такие как
операторы, идентификаторы, константы, переменные, функции, процедуры и т.д. В отличие
от естественных, язык программирования имеет ограниченный запас слов (операторов)
и строгие правила их написания, а правила грамматики и семантики, как и для любого
формального языка, явно однозначно и четко сформулированы.
Языки программирования, ориентированные на
команды процессора и учитывающие его особенности, называют языками низкого уровня. «Низкий уровень» не означает неразвитый,
имеется в виду, что операторы этого языка близки к машинному коду и
ориентированы на конкретные команды процессора. Языком самого низкого уровня является
ассемблер. Программа, написанная на нем, представляет последовательность команд
машинных кодов, но записанных с помощью символьных мнемоник.Языки программирования, имитирующие естественные, обладающие укрупненными командами, ориентированные
«на человека», называют языками высокого уровня. Чем выше уровень языка, тем ближе структуры данных и конструкции,
использующиеся в программе, к понятиям исходной задачи. Особенности конкретных
компьютерных архитектур в них не учитываются, поэтому исходные тексты программ легко
переносимы на другие платформы, имеющие трансляторы этого языка. Разрабатывать программы
на языках высокого уровня с помощью понятных
и мощных команд значительно проще, число ошибок, допускаемых в процессе программирования,
намного меньше. В настоящее время насчитывается несколько сотен таких языков.
С
помощью языка программирования создается текст программы,
описывающий разработанный алгоритм. Чтобы программа была выполнена, надо либо весь
ее текст перевести в машинный код (это действие и выполняет программа - компилятор)
и затем передать на исполнение процессору, либо сразу выполнять команды языка, переводя на машинный язык и исполняя каждую команду
поочередно (этим занимаются программы - интерпретаторы).
57. Понятие
грамматики. Формальное определение грамматики. Форма Бэкуса-Наура.
Грамматика , как наука, есть раздел языкознания, изучающий грамматический
строй языка, закономерности построения правильных осмысленных речевых отрезков на
этом языке
Формальная грамматика или просто
грамматика в теории формальных языков
— способ описания формального языка, то есть выделения некоторого подмножества из
множества всех слов некоторого конечного алфавита. Различают порождающие
и распознающие (или аналитические) грамматики — первые задают правила,
с помощью которых можно построить любое слово языка, а вторые позволяют по данному
слову определить, входит оно в язык или нет.
Форма Бэкуса—Наура (сокр.
БНФ, Бэкуса—Наура форма) — формальная система описания синтаксиса, в которой одни синтаксические
категории последовательно определяются через другие категории. Используется для
описания синтаксиса языков программирования, данных, протоколов (например, в документах
RFC) и т. д.
БНФ-конструкция определяет конечное число символов (нетерминалов
). Кроме того, она определяет правила замены символа на какую-то последовательность букв (терминалов) и символов. Процесс получения цепочки букв, можно определить поэтапно: изначально имеется один символ (символы обычно заключаются в угловые скобки, а их название не несёт никакой информации). Затем этот символ заменяется на некоторую последовательность букв и символов, согласно одному из правил. Затем процесс повторяется (на каждом шаге один из символов заменяется на последовательность, согласно правилу). В конце концов, получается цепочка, состоящая из букв (и не содержащая символов). Это означает, что полученная цепочка может быть выведена из начального символа. БНФ-конструкция состоит
из нескольких предложений вида
<определяемый символ> ::= <посл.1> | <посл.2> | . . . |
<посл.n>, описывающих правила.
Вот пример БНФ-конструкции, описывающей правильные скобочные последовательности:
<правпосл>::=<пусто>
| (<правпосл>) | <правпосл><правпосл>
58. Классификация грамматик. Четыре
типа грамматик по Хомскому.
59. Классификация языков. Примеры классификации
языков и грамматик.
Язы́к — знаковая система, соотносящая понятийное содержание и типовое звучание
(написание).
§ человеческие языки (предмет изучения лингвистики):
§ естественные человеческие языки,
§ искусственные языки для общения людей (например,
эсперанто),
§ компьютерные языки (например, Алгол, SQL),
Классификация языков (естественных)
Существует несколько способов классификации языков:
1.
ареальная, по культурно-историческим
ареалам (месту распространения);
2.
типологическая; например,
по способу выражения грамматического значения языки делят на
Классы языков программирования
- Функциональные
- Процедурные (императивные)
- Стековые
- Векторные
- Аспектно-ориентированные
- Декларативные - это языки программирования высокого уровня, в которых программистом не задается пошаговый алгоритм
решения задачи ("как" решить задачу), а некоторым образом описывается,
"что" требуется получить в качестве результата. Механизм обработки
сопоставление по образцу декларативных
утверждений уже реализован в устройстве языка. Типичным примером таких языков
являются языки логического программирования (языки, основанные на системе
правил).
- Динамические - позволяет определять типы данных и осуществлять
синтаксический анализ и компиляцию «на лету», непосредственно
на этапе выполнения. Динамические языки больше подходят для быстрой разработки
приложений. К динамическим языкам
- Прототипные
- Объектно-ориентированные
- Рефлексивные
- Логические
- Параллельного программирования
- Скриптовые (сценарные)
- Эзотерические
- C русским синтаксисом
Классификация
грамматик (грамматики классифицируются по виду их правил вывода)
60. Понятие системы программирования, её состав.
61. Принципы функционирования систем
программирования. Современные системы программирования. Примеры.
Цикл разработки
включает в себя следующие этапы:
62.Средства тестирования и отладки программ.
Отладка и тестирование программ
- Синтаксическая ошибка. Неправильное
употребление синтаксических конструкций, например употребление оператора цикла
For без то или Next.
- Семантическая ошибка. Нарушение
семантики той или иной конструкции, например передача функции параметров, не
соответствующих ее аргументам.
- Логическая ошибка. Нарушение логики программы, приводящее
к неверному результату. Это наиболее трудный для "отлова" тип ошибки,
ибо подобного рода ошибки, как правило, кроются в алгоритмах и требуют тщательного
анализа и всестороннего тестирования.